Tip 1: Hoe Sigma te vinden
Tip 1: Hoe Sigma te vinden
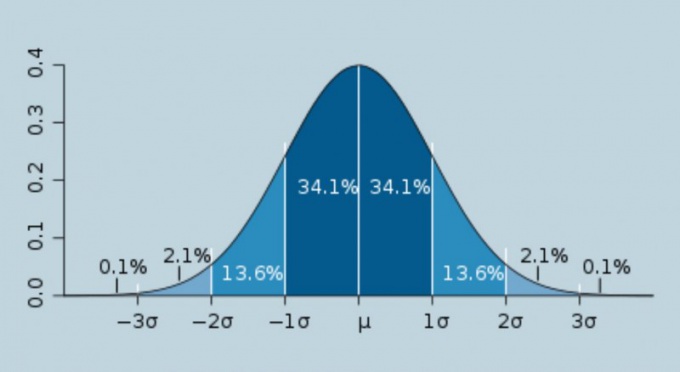
"Sigma", de letter van het Griekse alfabet σ, is genomennoem de constante waarde van de root-mean-square fout van de willekeurige meetfouten. De berekening van sigma wordt veel gebruikt in de natuurkunde, statistiek en aanverwante gebieden van menselijke activiteit. Het algoritme voor het berekenen van de sigma wordt hieronder weergegeven.
Je hebt nodig
- • Een array met gegevens voor het berekenen van sigma;
- • Formules voor berekening;
- • Calculator of computer waarop Microsoft Excel-software is geïnstalleerd.
instructie
1
2
3
Bereken sigma in de praktijk. Schrijf de waarden van alle metingen op in één kolom. Bereken het rekenkundig gemiddelde voor alle waarden, ze bij elkaar optellen en delen door het aantal waarden.
4
Trek vanuit het rekenkundig gemiddelde elke i-de waarde af en teken deze vierkant. Tel alle waarden bij elkaar op en deel het resultaat door n-1 (aantal waarden min één).
5
De verkregen waarde in statistieken wordt dispersie genoemd. We halen er de vierkantswortel uit. Als gevolg hiervan krijgen we de standaard root-mean-square error, de sigma genoemd.
6
Deze berekeningen kunnen standaard worden uitgevoerdpakket voor het werken met Microsoft Excel-spreadsheets. Ze kunnen zowel stapsgewijs als hierboven beschreven worden gedaan, of eenvoudigweg door de STDEV-functie toe te wijzen. Controleer van tevoren of de cel met de waarden een numeriek formaat heeft. Zorg ervoor dat u het bereik van waarden specificeert voor het berekenen van de sigma.
Tip 2: Hoe de mode voor statistieken te vinden
Statistieken zijn een functie van de resultaten van observaties,met behulp waarvan men een schatting van de onbekende distributieparameter kan vinden. Voor een dergelijke eigenschap van een statistische verdeling als modus, wordt de schatting niet berekend, maar geselecteerd na de primaire statistische verwerking van het beschikbare monster. Alleen in individuele gevallen en alleen na het verkrijgen van een theoretische verdeling mode kan worden gevonden door andere numerieke kenmerken.

instructie
1
Volgens de literatuurgegevens is de modus discreetwillekeurige variabele (de aanduiding Mo) is de meest waarschijnlijke waarde ervan. Een dergelijke definitie is niet van toepassing op continue verdelingen, voor hen is dit de waarde van de willekeurige variabele X = Mo, waarbij het maximum van de waarschijnlijkheidsdichtheid W (x) wordt bereikt. W (Mo) = max. Daarom moeten we voor theoretische verdelingen de afgeleide van de waarschijnlijkheidsdichtheid nemen, de vergelijking W '(x) = 0 oplossen en de wortel gelijk aan de modus stellen. Sommige distributies hebben geen modus (antimodaal). De bekende uniforme verdeling is modelless. Er zijn ook multimodale gevallen. Mo verwijst naar de kenmerken van de positie van de willekeurige variabele.
2
Voor statistische verdelingen wordt de modus gekozenPraktisch hetzelfde. Voer allereerst de verwerking van het beschikbare monster uit met behulp van wiskundige statistieken. Als er een steekproef is van de waarden van een opzettelijk discrete willekeurige variabele, accepteer dan de waarde van de modus Mo * als gelijk aan de waarde die vaker werd aangetroffen dan andere. Tegelijkertijd is het niet nodig om een polygoon te bouwen.
3
Bij het verwerken van de experimentele gegevens verkregen inAls resultaat van waarnemingen van een continue willekeurige variabele, wordt het gehele monster verdeeld in afzonderlijke bits en worden de frequenties van deze bits berekend als pi * = ni / n. Hier is ni het aantal waarnemingen per i-de cijfer, en n is de steekproefomvang. In de eerste benadering kunnen pi * worden beschouwd als waarschijnlijkheden van discrete waarden van een willekeurige variabele. Gebruik voor de waarden zelf cijfers die overeenkomen met het midden van de cijfers. Omdat Mo * dat nummer neemt, wat overeenkomt met de grootste frequentie.
4
De evaluatie van de modus kan bijvoorbeeld inradiocommunicatie, voor de ontwikkeling van ontvangers die optimaal zijn aan de hand van het criterium van de maximale a posteriori waarschijnlijkheidsdichtheid. Het is strikt genomen niet nodig om Mo * als het midden van de meest waarschijnlijke ontlading te kiezen. Net binnen elk van de categorieën wordt de verdeling als uniform beschouwd. Daarom is Mo * in dit geval meer een interval dan een puntschatting, en met gelijke waarschijnlijkheid kan het gelijk zijn aan een willekeurig aantal van het geselecteerde cijfer.







